Echtzeit-Daten - Rückblick nach über einem Monat
Unser erster Post Echtzeit-Daten - Probleme und Lösungen ist nun vor mehr als einem Monat erschienen und endete mit den Worten:
Noch haben wir keine Pipeline fertig, die die Echtzeitdaten parst, in eine Datenbank schreibt, mit den Fahrplandaten zusammen führt, statistische Auswertungen generiert… sondern einfach nur ein Shellscript, das die Daten herunterlädt und zippt, damit unsere Micro-SD-Karte im Raspberry Pi nicht so schnell voll ist.
Seit dem Abend des 12.03.2020 sammeln wir damit jene Echtzeitdaten im 2-Minuten-Takt, und wenn das nachfolgende Badge nichts gegenteiliges sagt, dann sammeln wir noch heute…
Was ist seitdem passiert?
Veränderungen bei der Datensammlung
Nun, wir haben durchgängig weiter alle zwei Minuten Daten gesammelt, und haben dabei insgesamt etwa 12 Minuten Downtime gehabt, die praktisch komplett auf kurzfristige Ausfälle bei den Datenanbietern zurück gehen. Unsere Prozesse haben sich in der Zeit gewandelt, und ein großer Teil des letzten Monats ist in eben diese Umstellungen geflossen.
Außerdem haben wir damit begonnen, die gesammelten Daten zu analysieren. Dazu weiter unten mehr.
Docker
Klar, man muss nicht alles mit Docker machen, nur weil es geht. Aber es ist schon echt praktisch, vor allem wenn eh schon Docker-Kenntnisse im Team vorhanden sind. Dass wir in dystonse-docker einen Stack aus mysql, phpmyadmin, unserem (namenlosen) Datensammelskript und dystonse-gtfs-data haben, die wir mal eben auf jedem unserer Rechner hochfahren können, hat uns viel Ärger gespart und den reibungslosen Umzug auf die “neue” Hardware ziemlich trivial gemacht.
Hardware
Unser Raspberry Pi 3 Model B+ würde früher oder später an seine Grenzen stoßen. Wir haben daher einen alten MacMini aus dem Jahr 2010 herausgeputzt, der sich derzeit recht gut als Datensammler und Datenbank-Server schlägt. 8 GB RAM und eine “richtige” Festplatte sind natürlich nicht die Traumausstattung für eine Datenbank. Aber da wir darauf nativ Linux booten, laufen Docker-Container dort schonmal um ein Vielfaches (!) performanter als auf einem MacBook Pro von 2018 unter MacOS. Vom Raspberry Pi ganz zu schweigen…
Wobei wir mit dem Raspberry Pi eh nicht nur Performance- und Kapazitätsprobleme hatten. Docker läuft darauf zwar ganz ordentlich - aber die Toolchain, um Multiarch-Dockerimages zu bauen (also solche, die z.B. sowohl auf amd64- als auch armv7-Architektur laufen) ist noch immer etwas unhandlich und leider auch fehlerhaft. Beim Versuch, das zu beheben, sind wir erstaunlich tief in sämtliche Abstraktionsschichten des ganzen Stacks abgetaucht, letztlich aber ohne Lösung. Das ist sehr schade, eine kleine Farm aus Pis hätte eigentlich ganz gut in unserem Home Office ausgesehen…
Datenbank
Zuvor hatten wir sowohl Echtzeitdaten als auch Fahrpläne nur als zip-Datei archiviert.
Bei den Fahrplänen waren wir uns nicht sicher, ob wir die überhaupt in einer relationalen Datenbank brauchen. Es gibt dazu das Tool gtfsdb, das wir zwar leicht zum Laufen bekamen, aber das für den Praxiseinsatz einfach zu langsam war. Mehrere Stunden warten, um einen Fahrplan zu importieren? Nein Danke.
Zwischenzeitlich haben wir überlegt, die Fahrpläne, die wir täglich herunter laden, zu entpacken und die einzelnen csv-Dateien per git zu versionieren. Auch da zeigte sich: Die Datenmengen, und vor allem auch die Menge der Änderungen, die da von Tag zu Tag auftreten, sind zu groß für git.
Wir haben noch eine andere Idee entwickelt, wie sich die Fahrpläne vielleicht platzsparend archivieren lassen. Dazu würden wir ihre Inhalte auch in eine Datenbank schreiben und jeden Datenpunkt mit einer Information versehen, in welchem Zeitraum er jeweils aktuell ist (bzw. war). Dadurch könnten wir eine Menge Redundanz einsparen, wenn es so funktioniert, wie erhofft - aber ausprobiert haben wir das bisher noch nicht, da wir im Moment auch mit den zip-Dateien noch ganz gut arbeiten können, und den Aufwand, ein weiteres Import-Tool zu schreiben, erstmal vertagt haben.
Es bleibt also dabei, dass die Fahrpläne nur als zip-Datei herum liegen. Für die Echtzeitdaten wäre das keine Lösung, denn hier brauchen wir dringend Analysen, die sich über große Teile unserer gesammelten Daten erstrecken, und dazu braucht es mindestens eine relationale Datenbank. Vielleicht stellen wir auch bald fest, dass wir NoSQL / Data Warehouse / Big Data / Blockchain brauchen…? Letzteres war natürlich nur ein Scherz, und für den Moment versuchen wir es mit einer sehr simplen ein-Tabellen-Lösung in MySQL.
Importer
Um die Echtzeitdaten in unsere Datenbank zu bekommen, haben wir ein eigenes Tool geschrieben. Sicher hätte es auch hier fertige Lösungen gegeben, aber die Gründe für eine eigene Implementierung haben überwogen:
- Wir brauchen nur einen ganz bestimmten Anteil der GTFS-rt-Daten.
- Wir wollen mittelfristig auch Daten aus anderen Formaten in das selbe Schema speichern können.
- Eigene Anforderungen an die Verknüpfung mit Fahrplandaten (die selbst nicht in der Datenbank liegen).
- Ein paar Überprüfungen sollen schon beim Import geschehen.
- Wir konnten so eine mittelmäßig komplexe Aufgabe gut gebrauchen, um unsere neuen Kenntnisse in der Sprache Rust auch praktisch zu üben.
Rust ist eine eigenwillige, aber ansonsten ganz wunderbare Sprache, und nachdem wir nun unseren Importer darin geschrieben haben, verfestigt sich die Überzeugung, dass es richtig ist, das Kernstück von dystonse (nämlich unsere Routensuche) darin neu zu schreiben. Als erstes Projekt in Rust erstmal “etwas kleines” wie den Importer zu schreiben, war in jedem Fall gut - gleich mit der Suche zu beginnen, hätte wahrscheinlich furchtbaren Chaoscode ins Herzstück unserer Anwendung gepflanzt. Stattdessen haben wir nun etwas kleineres Chaos an einem Ort, wo es verkraftbar ist.
Was ursprünglich dystonse-gtfs-importer war, ist in seiner Komplexität nach und nach gestiegen und fungiert nun als Multifunktionswerkzeug dystonse-gtfs-data für verschiedene Dinge, die wir mit unseren Daten so machen. Und dank fertiger Crates (so heißen die Pakete in Rust) wie gtfs-structures und gtfs-rt können wir uns hier auf unsere Anwendungslogik konzentrieren, während das Parsen der beiden Eingabeformate im Wesentlichen fertig und dennoch anpassbar ist.
Datenquellen
Durch einen Hinweis der MITFAHR|DE|ZENTRALE sind wir zusätzlich zu den Daten des VBN (Verkehrsverbund Bremen/Niedersachsen) auch auf ebenso offene Daten des VRN (Verkehrsverbund Rhein Neckar) gestoßen. Und dank der Kapselung mit docker-compose sind es für uns tatsächlich nur wenige Minuten Aufwand, eine weitere Quelle in unsere kontinuierliche Sammlung mit aufzunehmen. Seit dem 31.3. sammeln wir daher jetzt zusätzlich auch Echtzeit-Daten aus dem VRN.
Analyse der Daten
Eigentlich geht es darum, aus den gesammelten Daten Verspätungsmodelle abzuleiten, und damit genauere Prognosen für die nahe Zukunft zu generieren, als die Verkehrsbetriebe bisher bieten können. An dieses große Ziel tasten wir uns derzeit langsam heran.
In einem ersten Schritt wollten wir wissen: wie viele Daten haben wir eigentlich, und wie sind diese über die Zeit verteilt? Gleichzeitig stellt sich auch die Frage: wie sollen unsere Analysen generell ablaufen, d.h. wie spielen Datenbank, eigene Tools, vorhandene Standardsoftware und die Fahrpläne außerhalb der Datenbank zusammen?
Quantitative Betrachtung
Unsere Datenbank hat kürzlich die 50 Millionen Einträge geknackt, und ist nun über 9GB groß - also größer als der Arbeitsspeicher unseres DB-Servers. Einfache, unschuldig wirkende Queries brauchen da ohne passenden Index mindestens 30 Minuten und ebenso einfache, trotz scheinbar passender Indizes auch mal mehr als 24 Stunden. Ab und zu bewirken Indizes dann doch noch Wunder, wenn plötzlich nach 220 Millisekunden Ergebnisse vorliegen. Brauchen wir denn wirklich noch mehr Daten, die alles noch langsamer machen?
Aber betrachten wir doch zunächst, wann wir diese Daten gesammelt haben:
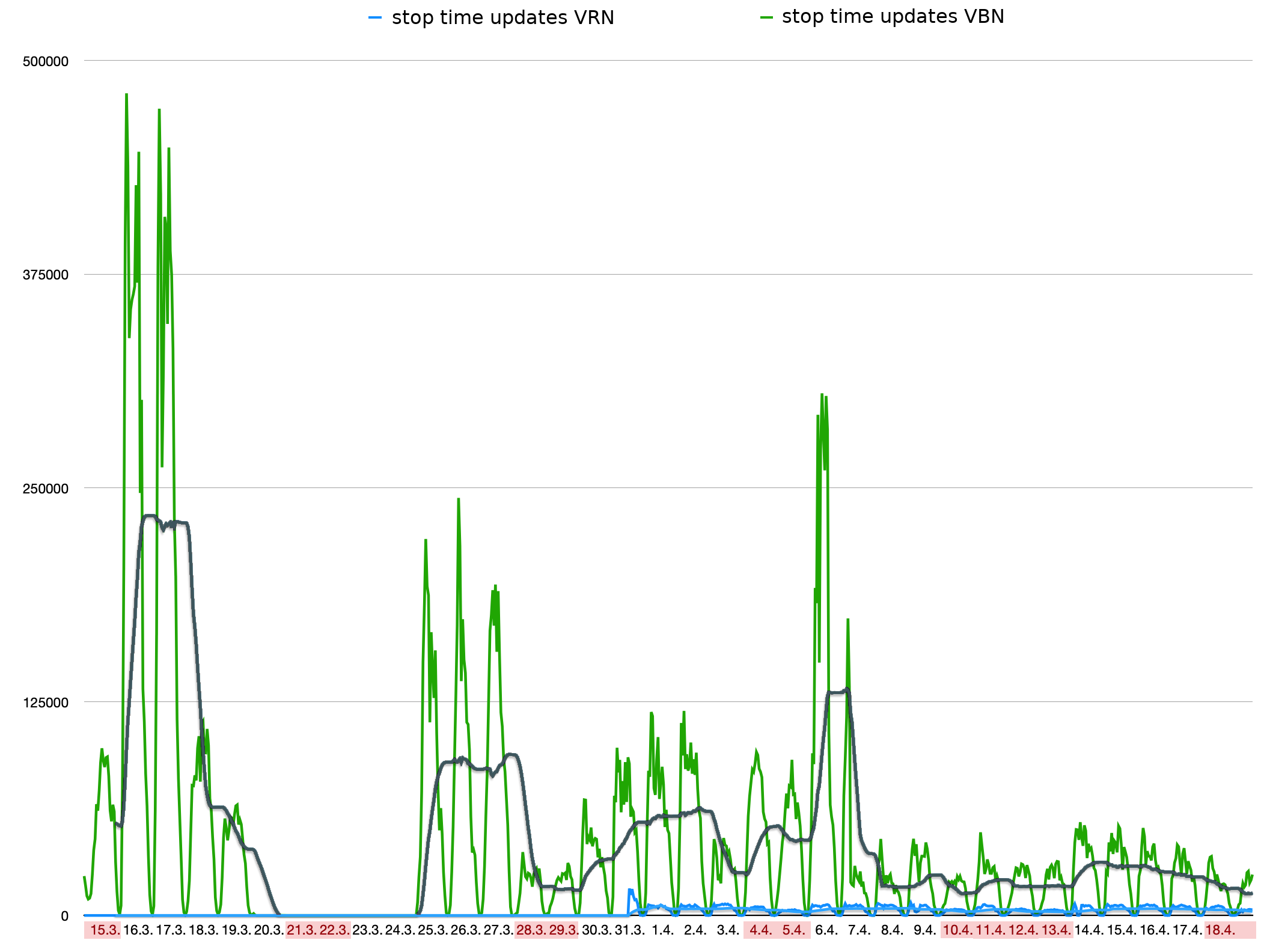
Was man hier sehen kann:
- Die Daten des VRN machen nur einen Bruchteil der Gesamtdatenmenge aus
- In den Nachtstunden gehen die neu eingehenden Daten praktisch auf Null zurück
- Vom 20.3. bis 24.3. haben wir einfach mal gar keine Datenpunkte aufgezeichnet. Nachforschungen ergaben: Auch da haben wir alle zwei Minuten einen validen Datensatz vom VBN erhalten, der aber einfach keine
stop_time_updatesenthielt. - Die Menge der Daten des VBN schwankt von Tag zu Tag enorm. Betrachtet man das Tagesmittel (die dunkelgraue Kurve ist ein rollender Mittelwert über 24 Stunden) lässt sich nur sehr schwach erahnen, dass an Wochenenden und Feiertagen (deren Daten rot hervor gehoben sind) weniger Verkehr als an anderen Tagen stattfindet.
Qualitative Betrachtung
Die heruntergeladenen Echtzeitdaten haben definitiv ihre Mängel. Unser Importer schreibt je Fehler eine Zeile in die Logdatei, und davon entstehen alle 2 Minuten gleich tausende. Die häufigsten Fehler sind falsch aufgebaute Protobuf-Dateien, sowie trip_ids, die in den Echtzeitdaten auftreten, aber keine Entsprechung in den Fahrplänen haben. Je Importversuch erhalten wir eine kleine Statistik wie die folgende:
import-vbn_1 | Done!
import-vbn_1 | Finished processing files.
import-vbn_1 | Schedule files : 1 of 1 successful.
import-vbn_1 | Realtime files : 1 of 1 successful.
import-vbn_1 | Trip updates : 559 of 1801 successful.
import-vbn_1 | Stop time updates: 2305 of 2305 successful.
import-vbn_1 | Finished one iteration. Sleeping until next directory scan.
(Dabei bezieht sich die Gesamtanzahl einer Zeile nur auf die erfolgreichen Elemente der vorherigen Zeile. Im konkreten Beispiel enthielten die 559 erfolgreichen trip updates insgesamt 2305 stop time updates, von denen alle erfolgreich waren. Wie viele stop time updates in den fehlgeschlagenen trip updates enthalten gewesen wären, ist nicht bekannt.)
Aber uns fehlt derzeit noch die Gesamtauswertung darüber. Ganz grob schätzen wir, dass 50% der erhaltenen Echtzeitdaten gar nicht erst in die Datenbank kommen, da sie zu unlesbar oder unvollständig sind, um sie sinnvoll weiter zu verarbeiten.
Was in der Datenbank landet, wirkt auf den ersten Blick überwiegend plausibel. Aber ehrlich gesagt: in den rohen Daten kann man eigentlich eh fast gar nichts sehen.
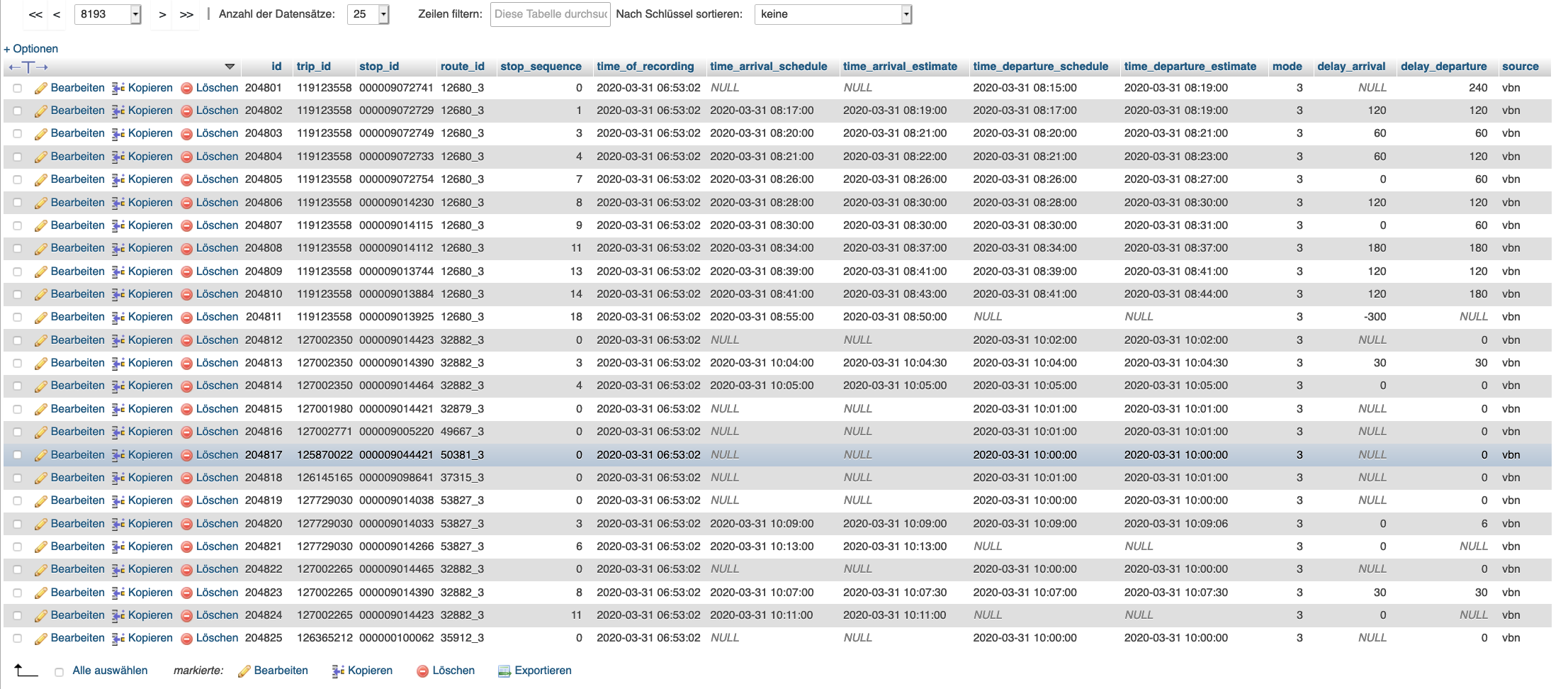
(Screenshot unserer Datenbank in phpmyadmin)
Es braucht also mehr, um einen Überblick über die Daten und ihre Qualität zu bekommen. Was liegt da näher als eine grafische Darstellung? Für getaktete Verkehrsmitel haben sich hier Bildfahrpläne bewährt, eine Spezialform des Weg-Zeit-Diagramms. Im Ergebnis zeigt sich dann anschaulich, wie gut die Qualität der Daten ist.
Auch schon auf dem Weg dorthin wird die Datenqualität sichtbar - jedoch nicht die inhaltliche, sondern die strukturelle. Wie viel Aufwand muss man noch treiben, wie viel Programmlogik bemühen, um aus den gesammelten Datenmengen die besagten Bildfahrpläne abzuleiten? Das Auswertungswerkzeug zu programmieren, war also nicht nur eine weitere Fingerübung in Rust, sondern auch ein guter Einstieg in den Umgang mit unseren Daten und ihrer Struktur.
Hier erstmal ein Ergebnis:
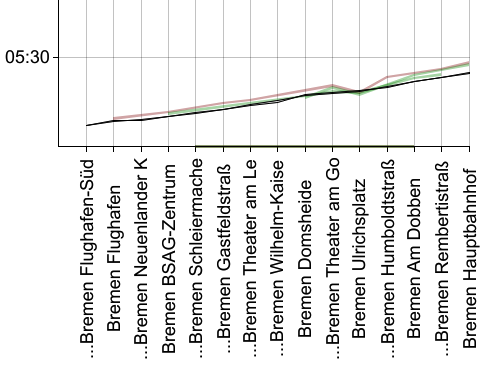
Zu sehen ist Straßenbahn-Linie 6 aus Bremen. Am unteren Rand sind Haltepunkte angegeben - nicht etwa alle Haltepunkte der Linie, sondern nur jene einer bestimmten, kurzen Linienvariante zwischen Flughafen Süd und Hauptbahnhof. Diese Variante ist schön übersichtlich, da es davon nur eine einzige Fahrt gibt (nämlich die um kurz nach fünf Uhr morgens).
Im Diagramm eingetragen sind die Sollzeiten laut Fahrplan (schwarz) sowie die Ist-Zeiten (farbig) der Fahrten, und zwar für alle bisher aufgezeichneten Tage. Grün sind dabei die Fahrten, die an Werktagen aufgezeichnet wurden, und rot die an Sonntagen. (Theoretisch gibt es auch gelbe Linien für Samstagsfahrten, aber die bekommen wir nur selten zu sehen - warum auch immer.)
Auf der selben Linie 6 gibt es noch weitere Linienvarianten, die andere bzw. mehr Haltepunkte anfahren. Wir kombinieren davon so viele wie möglich in einer gemeinsamen Grafik. In der nachfolgenden sind z.B. sieben Varianten vereint, die in verschiedenen Fahrtrichtungen zwischen Flughafen Süd und Universität Nord verkehren. Einige befahren nur (zusammenhängende) Teilstrecken davon, d.h. ihre Linien erstrecken sich nicht von ganz links nach ganz rechts im Diagramm (zu sehen vor allem zwischen 5:00 Uhr und 6:30 Uhr).
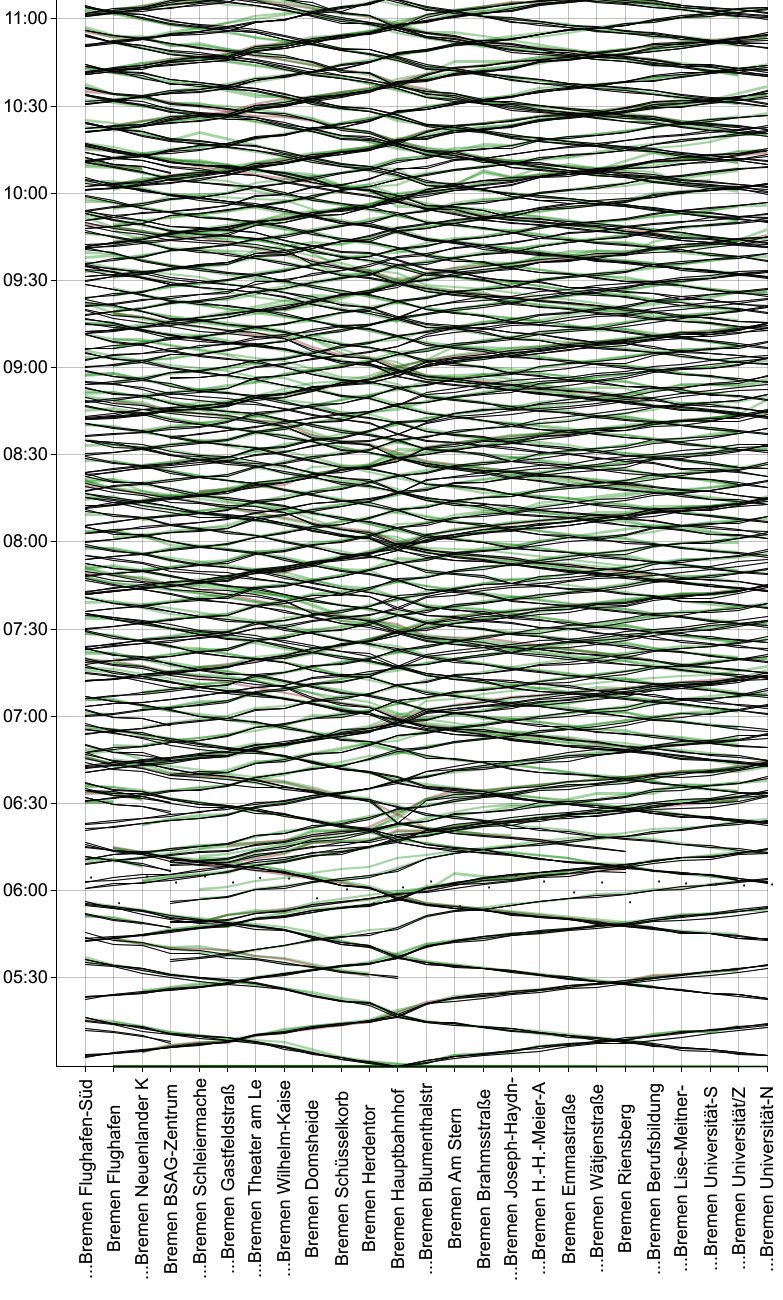
Was war alles nötig, um zu dieser Darstellung zu gelangen?
- Abfragen, für welche Linien (
"route") uns überhaupt Echtzeitdaten vorliegen - Die einzelnen Fahrten (
"trip") betrachten und zu Linienvarianten mit gleicher Abfolge der Halte ("route-variant") zusammenfassen - Finden von Linienvarianten, die sich gut in einem gemeinsamen Diagramm darstellen lassen
- Abfrage der Echzeitdaten für die jeweiligen Fahrten
- Aussortieren offensichtlich falscher Datenpunkte (noch nicht ganz fertig)
- Darstellung in einer Grafik (wir verwenden
plotters, sind damit aber nicht so ganz zufrieden. Bessere Vorschläge?)
Als Liste betrachtet, sieht das alles naheliegend und einfach aus. Zwischendurch haben wir aber auch Um- und Irrwege gemacht, so z.B. der Versuch, aus allen Linienvarianten eine Art “Master-Abfolge” zu finden, in der jede Variante gut darstellbar ist: Gleich unsere erste, quasi zufällig bestimmte Testlinie - der Bus 340 in Oldenburg - lieferte ein Beispiel für eine Linie, die sich eben nicht linear darstellen lässt. Stattdessen ergibt sich dieses Diagramm mit Verzweigungen und sogar Kreisen:
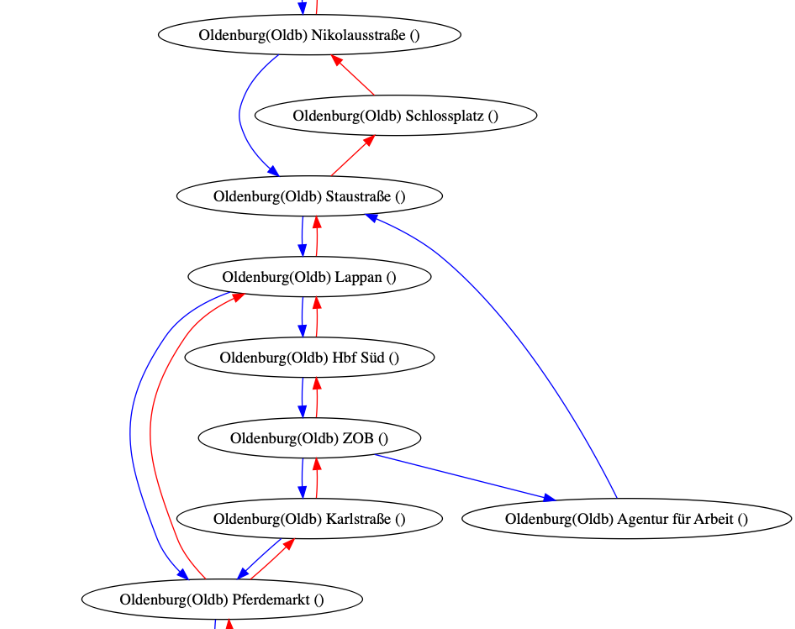
(Hier ein Link zur vollständigen Grafik, die ungefähr so lang ist wie der gesamte Blog-Post.)
{kind=link}
Auch Erinnerungen an den Busverkehr in Wernigerode wurden wach, und damit die Erkenntnis: Manche Buslinien lassen sich nicht in ein einzelnes Diagramm stopfen.
Qualität unserer Daten
Die oben genannte Vermutung hat sich bestätigt - nämlich dass die Daten, die es überhaupt in unsere Datenbank geschafft haben, im Wesentlichen von guter Qualität sind.
Die Echtzeitdaten haben grob die gleiche Form wie die Daten aus dem Fahrplan, und gleichzeitig gibt es praktisch keine Daten, die ganz unrealistisch 100% Pünktlichkeit anzeigen.
Auf manchen Linien sind die Daten allerdings eher dünn und lückenhaft:
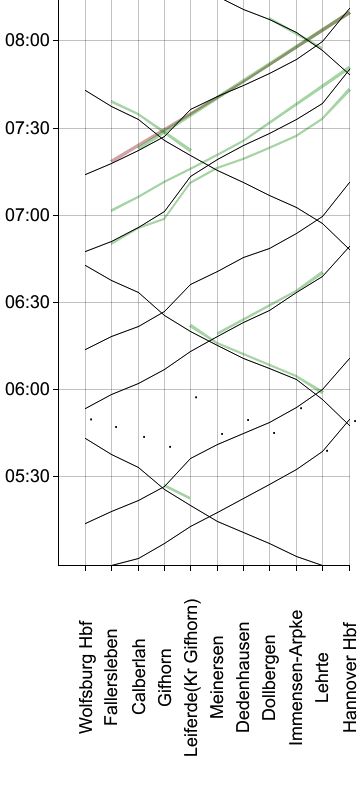
(Zuglinie RE 30)
Und an einigen Orten - also kurzen Abschnitten bestimmter Linien - treten sehr oft unplausible Datenpunkte auf, etwa dass ein Bus die ganze Zeit ca. 15 Minuten verspätet fährt, dann für zwei Halte fast pünktlich ist, und danach wieder mit ca. 15 Minuten Verspätung weiter fährt. Interessanterweise ist die Verspätung dort nicht null, und ob sie 0 ist, müssen wir nochmal prüfen. Diese Datenpunkte herauszufiltern, wird uns vermutlich noch etwas Arbeit bereiten.

(Buslinie 340 in Oldenburg)
Aber auch Ausreißer in die andere Richtung kommen vor:
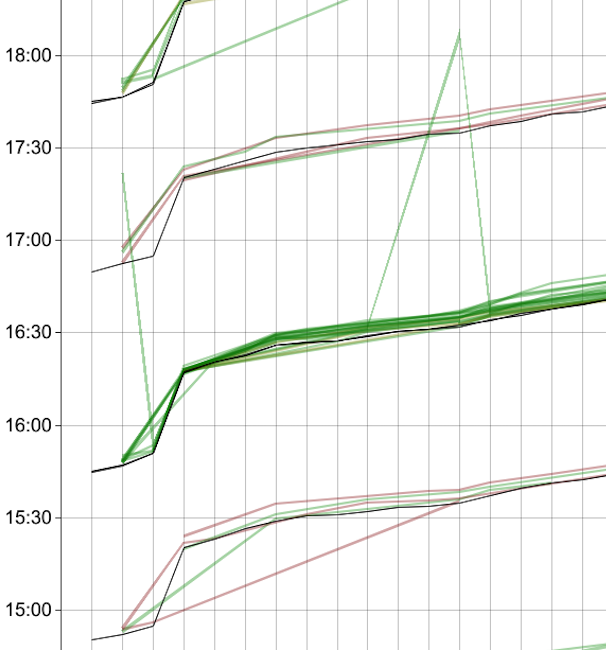
(Buslinie 440 in Oldenburg)
Fazit und Ausblick
Die grafische Darstellung zeigt uns nicht nur die Qualität unserer Daten (und die ist eigentlich ganz gut: Wir mussten erstaunlich lange suchen, um überhaupt Beispiele offensichtlicher Fehler für diesen Text zu finden).
Die Daten bildlich zu sehen erlaubt uns einen anderen Blickwinkel auf die Quantität unserer Daten. Auf einmal scheinen 50 Millionen Datensätze gar nicht mehr so viel, und auf gar keinen Fall zu viel. Für kaum eine Linie ergibt sich ein dichtes Bündel aus sich überlagernden Linien, und bei vielen ist jede einzelne Fahrt mit bloßem Auge gut ersichtlich. Statistisch signifikante Ergebnisse werden wir damit erstmal nur für sehr wenige Linien erreichen.
Können wir einfach abwarten, bis genug Daten angekommen sind? Oder müssen wir mal näher ergründen, warum wir für manche Linien nur eine Handvoll aufgezeichneter Fahrten haben, wenn doch die technische Ausstattung offensichtlich vorhanden ist? Oder doch noch weitere Datenquellen anzapfen, bei denen dichtere Daten geliefert werden?
Wir werden sehen…
Wer’s genau wissen will
Sämtliche Bildfahrpläne, die wir bisher generiert haben (bisher etwa 600 Grafiken für knapp 200 Linien von 28 Betreibern) können hier gezippt herunter geladen werden. (183 MB gezippt, 243 MB entpackt)
Leseempfehlungen
Bei unseren Recherchen sind wir auf die folgenden Artikel gestoßen, die sehr inspirierend sind:
- “Using Countdown Clock Data to Understand the New York City Subway” von Todd W. Schneider. Darin werden am Beispiel der New Yorker U-Bahn Abschätzungen zu Wartezeiten gemacht. Da diese U-Bahn nach keinem festen Takt fährt, ist das aber nur eingeschränkt mit unserer Arbeit vergleichbar.
- “How 2 M.T.A. Decisions Pushed the Subway Into Crisis” enthält wunderbare, interaktive Erklärungen zu Verspätungen und wie diese sich auf nachfolgende Fahrzeuge auswirken. Die sich dynamisch verändernden Bildfahrpläne sind ein absolutes Highlight!